


Il digital labour all’interno dell’economia delle piattaforme
Il caso di Facebook
di Andrea Fumagalli, Stefano Lucarelli, Elena Musolino, Giulia Rocchi
La versione originale inglese di questo saggio è stata pubblicata sulla rivista Sustainability, giugno 2018. Effimera.org ringrazia gli autori per la traduzione in italiano del testo
 1. Introduzione
1. Introduzione
Nonostante lo scoppio della bolla Internet alla fine degli anni ’90, la diffusione delle tecnologie dell’informazione e della comunicazione (ICT) continua a segnare gli anni 2000. Soprattutto negli ultimi anni abbiamo assistito ad una significativa accelerazione tecnologica. Diversi settori sono stati colpiti. Si tratta di industrie che hanno sempre più a che fare con la gestione della vita umana (ad esempio, lo Human Genome Project, iniziato nel 1990 e conclusosi nel 2003, ha aperto enormi spazi nella possibilità di manipolazione della vita individuale e della sua procreazione [1]). Come sottolineato da Robert Boyer “questo tipo di modello di crescita è un’estensione della continua trasformazione che è proseguita a partire dalle potenzialità dell’economia dell’informazione” [2]. Se il paradigma tecnologico dell’ICT ha colpito duramente i livelli occupazionali nell’industria manifatturiera, la nuova ondata biotecnologica rischia di avere effetti ancora maggiori sui settori terziari tradizionali e avanzati, che negli ultimi decenni hanno svolto un ruolo compensativo contro la perdita di posti di lavoro nei settori tradizionali.
Lo sviluppo di algoritmi di seconda generazione [3] permette un processo di automazione senza precedenti nella storia dell’umanità. Applicati alle macchine utensili, attraverso le tecnologie informatiche e le nanotecnologie, sono in grado di trasformarle in strumenti e mezzi di produzione sempre più flessibili e duttili. Gli algoritmi di seconda generazione si differenziano dalla prima generazione per la loro natura cumulativa di auto-apprendimento, configurando così un nuovo rapporto tra uomo e macchina. Infatti, dopo la prima fase di implementazione e creazione, grazie al comportamento umano, sono in grado di operare in una condizione quasi totale di automazione (machine learning). Le tecnologie attuali, tuttavia, non possono operare senza l’accelerazione (rispetto al recente passato) del grado di raccolta e manipolazione di una grandissima quantità di dati in spazi sempre più ristretti e con una velocità sempre maggiore. Già nel 2011, una ricerca del McKinsey Global Institute ha esaminato lo stato dei dati digitali e ha riconosciuto il grande potenziale di valore economico che questi possono creare:
“Ci sono cinque grandi modi in cui l’utilizzo dei big data può creare valore. In primo luogo, i big data possono sbloccare un valore significativo rendendo le informazioni trasparenti e utilizzabili a frequenze molto più elevate. In secondo luogo, poiché le organizzazioni creano e memorizzano più dati transazionali in forma digitale, possono raccogliere informazioni sulle prestazioni più accurate e dettagliate su tutto, dalle scorte di prodotti ai giorni di malattia, rendendo esplicita così la variabilità [dei dati] e aumentando le prestazioni. Le aziende leader utilizzano la raccolta e l’analisi dei dati per condurre esperimenti controllati per prendere decisioni gestionali migliori; altre utilizzano i dati per le previsioni di base a bassa frequenza per le previsioni ad alta frequenza, che ora stanno lanciando per regolare le leve di business just in time. In terzo luogo, i big dataconsentono una segmentazione sempre più stretta dei clienti e quindi prodotti o servizi su misura in modo molto più preciso. In quarto luogo, un’analisi sofisticata può migliorare sostanzialmente il processo decisionale. Infine, i big data possono essere utilizzati per migliorare lo sviluppo della prossima generazione di prodotti e servizi”.[4]
Come sostenuto da Martin Kenney e John Zysman, tra gli altri, “la rivoluzione algoritmica e il cloud computing sono le basi dell’economia della piattaforma. Ma la potenza di calcolo è solo l’inizio della storia. Quella potenza di calcolo viene convertita in strumenti economici utilizzando algoritmi che operano sulla materia prima dei dati”. [5].
Nell’economia emergente delle piattaforme digitali, il dato come output finale, che diviene poi redditizio sui mercati globali della comunicazione e della pubblicità, dà origine a un “valore di rete” come risultato di un processo continuo e dinamico di interazione tra il lavoro umano e linguistico e le infrastrutture digitalizzate (le piattaforme) [6]. Condizione necessaria (anche se non sufficiente) perché un algoritmo possa essere sfruttato al massimo della potenza è l’esistenza di un processo di standardizzazione della catalogazione dei dati necessari in relazione allo scopo prefissato. Ciò è reso possibile dalle tecniche di manipolazione dei cosiddetti “big data“, in particolare le tecniche di analisi e di estrazione di big data per dati strutturati e non strutturati (comunemente chiamate “estrazione di dati”), così come spiegato nella letteratura sulla gestione tecnologica da AmirGandomi e Murtaza Haider [7]. I big datarappresentano non solo alcuni dei dati più granulari che siano mai esistiti, generati secondo per secondo da ogni dispositivo e software connessi al web, ma rappresentano anche uno strumento in grado di cambiare il significato profondo delle attività umane e in particolare del lavoro umano.
In Platform Capitalism, Nick Srnicek fornisce uno dei primi interventi di ispirazione marxista nel discorso sulla digitalizzazione trainata dai dati e sul futuro del lavoro [8]. Secondo Srnicek, l’evoluzione delle tecnologie di internet ha modificato radicalmente lo scenario dell’accumulazione di capitale e dei rapporti di proprietà tra le imprese, e legittima la seguente domanda: l’emergere del capitalismo delle piattaforme costituisce una nuova modalità di sfruttamento? Srnicek offre un quadro innovativo attraverso il quale affrontare la questione nella sua concezione dei dati come ‘materia prima’, ma la sua analisi si limita agli effetti delle così dette lean platforms sul mercato del lavoro.
Da una prospettiva marxiana, dovrebbero essere considerati altri due problemi:
- In che cosa consiste il processo di trasformazione delle informazioni personali in big data?
- E, inoltre, qual è l’origine del valore nell’economia delle piattaforme?
In questo contributo, partendo dall’esempio di Facebook, spieghiamo il processo di valorizzazione al centro del capitalismo delle piattaforme, sottolineando la rilevanza del digital labour come fonte di valore economico per un numero sempre maggiore di imprese alimentate dai dati.
L’obiettivo principale della Sezione 2 è la presentazione del modello di creazione di valore utilizzato da Facebook. Infatti, la società americana di servizi di social media online e social networking lanciata da Mark Zuckerberg rappresenta un esempio di piattaforma pubblicitaria in cui il valore si basa essenzialmente su un processo di espropriazione delle così dette life skills degli individui. Nel modo tradizionale, il capitalismo delle piattaforme ha a che fare principalmente con la soddisfazione di alcuni servizi rivolti ai consumatori e con la gestione dei settori legati alla logistica delle merci. Le industrie più colpite riguardano il settore terziario, anche se sono coinvolte in alcuni aspetti le industrie manifatturiere. Questa prospettiva sembra comune all’argomentazione di Nick Srnicek e al Report McKinsey sui big data. La loro analisi del capitalismo delle piattaforme non considera altre caratteristiche rilevanti del modello economico, in particolare il fatto che le attività umane sulle piattaforme Internet sono sempre più integrate con gli elementi digitali della comunicazione e del linguaggio, come sosteniamo nella Sezione 3. È quindi necessario chiarire la distinzione cruciale tra “labour” e “work” per proporre una definizione specifica di “digital labour”, come proponiamo nella Sezione 4 dopo aver discusso il concetto all’interno del dibattito marxiano. Ci riferiamo in particolare ai recenti contributi di Christian Fuchs e Sebastian Sevignani (2013) [9] e Trebor Scholz (2017) [10], mostrando la rilevanza delle tendenza al divenire rendita del profitto proposta innanzitutto da Carlo Vercellone (2010) [67]. La sezione 5 conclude il saggio.
- Il caso di Facebook
Come mostrato in Figura 1, Facebook è il leader mondiale indiscusso nel campo dei social network.
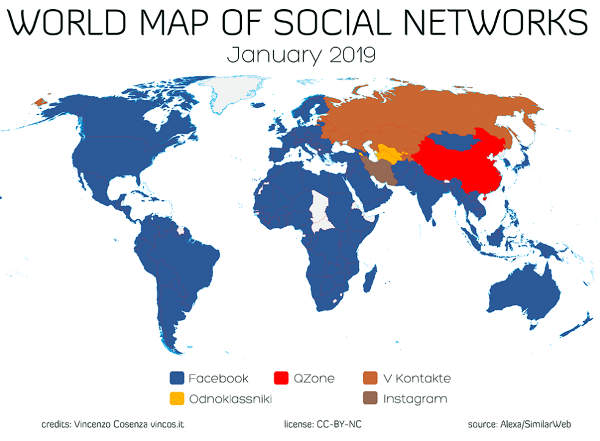
Figura 1. Mappa mondiale dei social network. Fonte: http://vincos.it/world-map-of-social-networks.
A partire dal primo trimestre del 2017, il numero mondiale di utenti attivi mensili su Facebook ammonta a 1,94 miliardi, con un aumento del 17% rispetto all’anno precedente [11]. Un utente attivo mensile (MAU) è definito come un utente Facebook registrato che si è connesso e ha visitato Facebook attraverso il sito web o un dispositivo mobile, o ha utilizzato l’applicazione Messenger almeno una volta negli ultimi 30 giorni; questa metrica, oltre a quelle relative agli utenti attivi giornalieri (DAU) e al ricavo medio per utente (ARPU), non include gli utenti Instagram, WhatsApp e Oculus [12].
Secondo il Facebook Annual Report, il fatturato è stato di 27,64 miliardi di dollari nel 2016, in crescita del 54% su base annua, e i ricavi pubblicitari, che rappresentano la quasi totalità dell’importo citato, sempre più provenienti da dispositivi mobili che da computer desktop [13], sono stati di 26,89 miliardi di dollari, con un tasso di crescita addirittura superiore a quello del fatturato. Nel caso specifico di Facebook, i ricavi pubblicitari relativi ai dispositivi mobili hanno rappresentato circa l’83% dei ricavi pubblicitari totali nel 2016. Da dove viene questo valore?
2.1. Facebook: La creazione di un gigante
La storia del social network più popolare del mondo è nota. Le radici dell’azienda devono essere esaminate nel contesto accademico. La prima versione del sito, chiamata “Thefacebook” e fondata nel febbraio 2004 da Mark Zuckerberg-uno studente di psicologia all’Università di Harvard appassionato di programmazione dei software – poteva essere raggiunta solo da utenti che possedevano un indirizzo email Harvard.edu [14,15]. In considerazione del notevole successo ottenuto [16] – il sito ha registrato 1200 abbonamenti in 24 ore, coprendo oltre la metà della popolazione studentesca un mese dopo – la rete si è rapidamente espansa a tutte le università americane, è diventata “Facebook” nell’agosto 2005 e ha allargato il suo orizzonte ben oltre gli istituti universitari, diventando accessibile a qualsiasi utente almeno tredicenne con un indirizzo e-mail.
Nel corso di poco più di un decennio, Facebook ha acquisito 65 aziende (inclusi tutti gli asset) per un totale di oltre 23 miliardi di dollari di spesa, escludendo le somme di acquisizione non rivelate [17].
Questo grande blocco di acquisizioni può essere suddiviso in quattro segmenti principali, ognuno dei quali segue una precisa strategia di marketing legata alla graduale evoluzione dell’azienda:
- Il primo include tutti quegli acquisti volti a migliorare le funzionalità del sito Facebook: tra questi troviamo Friend Feed (un aggregatore di feed in tempo reale le cui funzioni “Mi piace” e “News Feed” sono diventate il marchio di fabbrica di Facebook dal 2009), Octazen Solutions (il cui servizio di contactimporter è stato incorporato in “Facebook Friend Finder” nel 2010), e DivvyShot (le cui tecnologie di photo-sharing sono state integrate in “Facebook Photos” nello stesso anno)
- Il secondo sottoinsieme comprende le acquisizioni necessarie per entrare nel settore degli smartphone: SnapTu (piattaforma applicativa per telefonia mobile) e Beluga (applicazione di messaggistica istantanea di gruppo e servizio web) rappresentano le basi di Facebook Mobile e Facebook Messenger (un’applicazione di messaggistica sia per computer mobili che desktop, separata dalla piattaforma Facebook). In questo settore, troviamo anche gli investimenti aziendali più costosi: nel 2012 Instagram (un social network di condivisione di foto ancora funzionante con il proprio marchio, anche se alcune delle sue caratteristiche sono state integrate in Facebook) è stato acquistato per 1 miliardo di dollari, mentre l’acquisizione di WhatsApp (un’applicazione di messaggistica per telefonia mobile praticamente gratuita) è stata valutata in 19 miliardi di dollari.
- Il terzo segmento riguarda l’implementazione del modello di raccolta pubblicitaria di Facebook. Nel 2013 l’azienda ha assorbito e ridisegnato la piattaforma di misurazione delle prestazioni delle campagne pubblicitarie Atlas Solutions, precedentemente di proprietà di Microsoft. Questa acquisizione ha permesso di abbinare le tecniche di tracciamento di Atlas sia con l’enorme repository di dati first-party di Facebook siacon dati di terze parti forniti da data brokers e relativi agli acquisti offline dei consumatori (Facebook ha collaborato con i data brokers Axciom, Epilson, Experian, Datalogix, Oracle e Quantium[18]). Invece del modello obsoleto basato sui cookies, che è diventato inaffidabile dopo l’avvento del mobilee il conseguente cambiamento nel comportamento di acquisto degli utenti, che si è spostato verso abitudini di acquisto cross-device (il che avviene quando un acquisto online coinvolge due o più dispositivi), questo investimento è apparso ad alcuni osservatori [19] come un tentativo di costruire una rete pubblicitaria al di fuori di Facebook, sfidando il dominio di Google nel display advertising on line (cioè quella forma di pubblicità che trasmette visivamente un messaggio commerciale utilizzando elementi grafici). La decisione, annunciata nel 2016, di spostare Atlas dal gruppo adtech di Facebook alla sua divisione di misurazione a causa di problemi di cattiva qualità e frode [20], ha portato alla chiusura immediata sia di Facebook Exchange [21] (un servizio desktop ad-exchange che permetteva a società terze di acquistare spot pubblicitari sul social network) sia di Live Rail [22] (una piattaforma di monetizzazione per video publishers, acquisito nel 2014 per mezzo miliardo di dollari). Questa decisione rispecchiava le intenzioni di Facebook di costruire un ecosistema pubblicitario digitale “off Facebook” chiuso e controllato centralmente, un “giardino recintato” che tiene i dati al riparo dall’accesso di altre parti, chiamato Facebook Audience Network [23]. Quest’ultimo, lavorando in sinergia con Facebook Ads Manager, rappresenta una fonte di reddito essenziale per l’azienda.
- Il quarto e ultimo segmento riguarda la diversificazione, ovvero le acquisizioni in settori diversi dal social advertising (la pubblicità sui social). Tuttavia, tali acquisizioni possono essere considerate ancora fortemente legate al core businessdi Facebook. Nel 2014 Facebook ha acquisito l’azienda tecnologica di realtà virtuale Oculus VR, la fitness/health tracking app ProtoGeo e l’azienda inglese Ascenta, produttrice di droni ad energia solare. Quest’ultima talent acquisition – combinata con un team composto da membri del NASA Jet Propulsion Laboratory, del NASA Ames Research Centre e del National Optical Astronomy Observator – è stata funzionale allo sviluppo di un progetto più ampio nell’ambito di un gruppo di ricerca e sviluppo appositamente creato, chiamato Connectivity Lab: Internet.org [24], in collaborazione con alcuni giganti dell’industria delle telecomunicazioni. Il progetto consiste in un’applicazione per dispositivi mobili con l’obiettivo di portare l’accesso a Internet a prezzi accessibili a quella parte ancora preponderante del mondo che non ha ancora sperimentato i “benefici della connettività”, ovvero l’utilizzo di veicoli come, appunto, aerei senza pilota ad alta quota alimentati a energia solare (cioè droni) e satelliti. La piattaforma è stata ribattezzata con il nome meno pretenzioso di “Free Basics” nel settembre 2015, dopo che diversi gruppi di attivisti per i diritti digitali di 31 paesi hanno firmato una lettera aperta [25] a Zuckerberg, dicendo che Internet.org, fornendo l’accesso a un piccolo e selezionato insieme di siti web e servizi piuttosto che a tutta Internet, “viola i principi di neutralità della rete, minacciando la libertà di espressione, le pari opportunità, la sicurezza, la privacy e l’innovazione”.
2.2. Il business model di Facebook
Secondo un’indagine di e-Marketer [26] rivolta a 551 social media marketers in tutto il mondo, Facebook è, per quasi il 96% del campione, la piattaforma di social media advertising più efficiente, con il più alto ritorno sull’investimento (ROI). Se si considera che la spesa per la pubblicità sui social a livello mondiale dovrebbe rappresentare il 20% di tutta la pubblicità su Internet entro il 2019 [27] e si prevede che supererà gli investimenti in pubblicità sui giornali, si può ragionevolmente pensare che la maggior parte di questa spesa finirà nelle mani della società di Menlo Park. Ciò che non può essere contestato in alcun modo è che Google e Facebook non sono due “concorrenti in una situazione di duopolio”, ma piuttosto due piattaforme indipendenti di monopolio pubblicitario su Internet che lavorano in modo complementare in due campi diversi, rispettivamente la pubblicità legata alla ricerca sul Web e la pubblicità sui social media, catturando insieme più della metà di tutta la crescita della spesa pubblicitaria globale [28].
Il modello di business di Facebook è diventato più simile a quello di Google grazie a Facebook Audience Network (FAN) e al suo strumento di gestione della pubblicità Facebook Ads Manager [29] nel 2014. FAN è un network focalizzato sui dispositivi mobili che fornisce agli inserzionisti nuovi mezzi per estendere le loro campagne oltre i confini di Facebook stesso, sfruttando l’ineguagliabile patrimonio di dati personali di Facebook e utilizzando gli stessi strumenti di targeting e misurazione altamente personalizzati disponibili per i normali annunci di Facebook: altre preziose fonti di informazione sono i pulsanti “Like” e “Sign in with Facebook” sparsi sul Web.
Questo cambiamento è avvenuto in fasi successive. FAN è stato concepito inizialmente come un network pubblicitario in-app che permetteva a qualsiasi inserzionista di acquistare spazi pubblicitari da qualsiasi sviluppatore di applicazioni di terze parti (non solo applicazioni create utilizzando Facebook for Developers [30]). Nel 2016 si è ampliato per includere, oltre alle applicazioni, anche siti web (di parti terze) per dispositivi mobili che hanno optato per la rete (un sito web per dispositivi mobili richiede la progettazione di un sito ad-hoc che coesiste con il sito navigabile da PC desktop o da PC portatili), ampliando ulteriormente la probabilità di raggiungere il giusto pubblico al di fuori di Facebook, ma limitandosi comunque agli utenti registrati su Facebook [31]. Nello stesso anno, l’azienda ha annunciato che anche le persone senza un account Facebook sarebbero diventate target di annunci pubblicitari [32]. È quindi chiaro che la FAN di Facebook opera allo stesso modo di Google Ad Sense.
Diamo ora un rapido sguardo al lato della domanda cui si rivolge il complesso marketing di Facebook[33].
Creando un account Business Manager, un inserzionista potrà sia autogestire le proprie pagine Facebook e i propri account pubblicitari, sia contare su agenzie di broker marketing ad hoc. Dopo aver impostato le informazioni sull’account (come la ragione sociale e l’indirizzo, la valuta, il fuso orario, ecc.), i dati di fatturazione e di pagamento e il budget pubblicitario mensile, gli inserzionisti potranno auto-organizzare la loro campagna pubblicitaria utilizzando l’account Facebook Ads Manager appena creato.
La figura 2 mostra come è strutturata una campagna Facebook, composta da uno o più insiemi di annunci a loro volta composti da uno o più annunci.
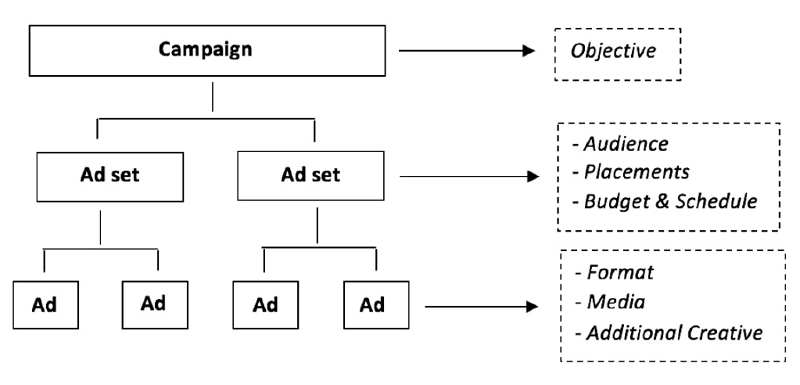 Figura 2. Struttura di una campagna pubblicitaria su Facebook.
Figura 2. Struttura di una campagna pubblicitaria su Facebook.
L’obiettivo finale della campagna determinerà i formati degli annunci e le opzioni di asta. Facebook offre una vasta gamma di obiettivi raggruppati in tre categorie principali: consapevolezza, considerazione e conversione. Una campagna può avere diversi set di annunci. In questa fase è possibile definire un target di pubblico, sulla base di tre tipi primari di audience (saved, custom e look a like) e sfruttandone la localizzazione, la demografia, gli interessi, i comportamenti, il traffico del sito web e il coinvolgimento (il così detto engagement). I posizionamenti degli annunci possono essere lasciati alla scelta automatica di Facebook o configurati manualmente: appariranno sul desktop o sui dispositivi mobili (o su entrambi) e in più luoghi, tra cui: Facebook News Feed, colonna di destra di Facebook, Instagram, Messenger e la rete esterna di Facebook, ovvero FAN.
Il terzo passo consiste nell’assegnazione di un budget (giornaliero o fisso, basato su una strategia di offerta Cost-Per-Click-CPC, Cost-Per-Mille-CPM o Cost-Per-Action-CPA) e un calendario (scegliendo in quali giorni della settimana e fasce orarie gli annunci saranno visualizzati). La pubblicazione dell’annuncio avviene nell’ambito di un’asta mondiale a cui si aggiungono centinaia di migliaia di inserzionisti. Ogni volta che si verifica un’asta, Facebook combinerà tre fattori (importo dell’offerta, punteggio di rilevanza e tasso di azione stimato) in un valore totale. L’annuncio con il valore totale più alto potrà apparire negli angoli più adatti dell’ecosistema di Facebook. Il primo fattore è la somma massima che l’inserzionista è disposto a pagare per vincere lo spazio pubblicitario ed è probabile che sia sempre inferiore all’importo effettivamente addebitato. Il secondo fattore è il gemello del Google Quality Score, un punteggio su una scala da 1 a 10 che valuta un annuncio in base alla sua rilevanza (cioè il livello di “attenzione” che l’annuncio riceve in termini di “Like”, azioni, commenti, click, conversioni, etc.). Ciò significa che puntare al pubblico giusto porterà ad un buon tasso di click-through rate (CTR) sull’annuncio, un rapporto che indica il numero di clic su un annuncio diviso per il numero di volte che l’annuncio viene visualizzato. Il CTR a sua volta abbasserà il CPC/CPM/CPA e aumenterà il punteggio di rilevanza. Infine, il tasso di azione stimato è una valutazione della probabilità che un utente compia le azioni necessarie per ottenere i risultati su cui l’inserzionista ha scommesso. Ogni annuncio può essere composto da un pacchetto di annunci, il cui formato (altamente personalizzabile), canale mediatico e spunti creativi aggiuntivi (per personalizzare ulteriormente l’annuncio) devono essere accuratamente scelti in base all’obiettivo della campagna.
Dal lato dell’offerta troviamo il suddetto Facebook Audience Network [34], che aiuta i publishers e gli sviluppatori a monetizzare i loro siti web mobili e gli inventari delle applicazioni ospitando annunci alimentati da Facebook che corrispondono agli interessi del loro pubblico, creando una sorta di “circolo virtuoso”, dove gli annunci che corrispondono alle predilezioni degli utenti portano a risultati migliori per gli inserzionisti, il che significa maggiori entrate pubblicitarie per i publishers e per gli sviluppatori. Grazie all’ineguagliabile conoscenza di Facebook delle abitudini, inclinazioni, gusti e così via, dei suoi iscritti, gli annunci hanno il potenziale per essere estremamente convincenti e i loro formati variano notevolmente: inative ads adattano il loro aspetto ai siti web e ai contenuti delle applicazioni, al fine di essere percepiti come consigli di acquisto non intrusivi, gli interstitia lads sono annunci a schermo intero che appaiono all’improvviso sullo schermo, mentre gli annunci video in streaming, ovvero video pubblicitari di 15/20 secondi mostrati agli utenti mentre guardano un video, sono tra i formati pubblicitari FAN più redditizi.
I flussi di reddito derivanti dai click (o dalle azioni di conversione, ovvero di acquisto dei prodotti/servizi sponsorizzati) sugli annunci inseriti nel Facebook News Feed, colonna di destra, Instagram e Messenger attraverso Facebook Ads Manager appartengono solo e soltanto a Facebook. Diversamente, Facebook condivide una percentuale del suo profitto pubblicitario con quei publishers e sviluppatori che, aderendo a FAN, inseriscono annunci pubblicitari all’interno dei loro siti e applicazioni mobile (questi ultimi concepiti sia attraverso “Facebook for Developers” o adottando qualsiasi altra piattaforma di app-building).
La figura 3 cerca di rappresentare in modo semplificato il modello di creazione di valore di Facebook.
- La piattaforma di Facebook offre agli utenti iscritti una vasta gamma di funzionalità tecnologiche gratuite.
- Gli utenti forniscono a Facebook (che prende nota di ogni singolo bit) informazioni di ogni tipo, da quelle più standard a quelle meno intuitive [35].
- Attraverso Facebook Ads Manager, gli inserzionisti acquistano slot pubblicitari da Facebook, sulla base di un meccanismo d’asta in tempo reale.
- Gli annunci sono visualizzati sui siti web/applicazioni dei publishers/sviluppatori che, essendo registrati a FAN (rete) attraverso FAN (strumento), sono pagati per ospitare annunci alimentati da Facebook.
- Gli annunci sono visualizzati anche sulla stessa piattaforma Facebook (Facebook News Feed per desktop e/o mobile, colonna di destra di Facebook, Instagram e Messenger).
- Gli spazi pubblicitari possono essere acquistati/offerti sia direttamente tramite FacebookAds Manager/FAN (strumento) o indirettamente tramite un’agenzia pubblicitaria.
- Le spese dell’inserzionista e i ricavi del publisher/sviluppatore non dipendono dall’acquisto effettivo del prodotto o servizio pubblicizzato, ma dal numero di click dell’utente sugli annunci, ovvero dalla mera “attenzione” che essi manifestano (per caso, errore o interesse reale) per gli annunci.
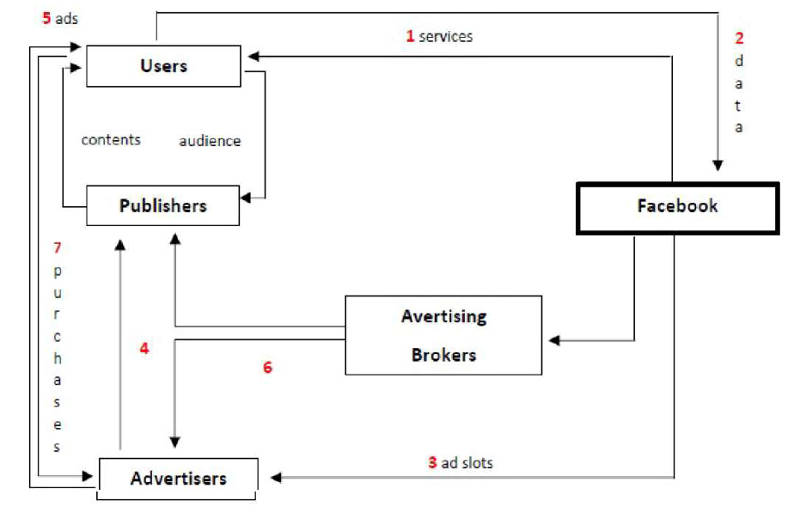
Figura 3. Il modello di creazione di valore: uno schema semplificato.
Rispetto a Uber, Deliveroo e Foodora, Facebook rappresenta una tipologia ideale diversa, in cui la prestazione lavorativa non è immediatamente percepibile come un campo di sforzi fisici e intellettuali. Infatti, il digitallabour su Facebook è la suddetta attività relazionale, o “lavoro” di riproduzione sociale [36]. Di conseguenza, il capitalismo delle piattaforme è un modo di produzione che determina un processo di accumulazione che si fonda non solo sullo sfruttamento della conoscenza, ma anche dell’insieme delle facoltà umane, da quella relazionale-linguistica a quella affettivo-sensoriale. Per questo motivo, Fumagalli e Morini hanno proposto l’uso del termine biocapitalismo [37,38].
Il processo di produzione da informazioni personali a big data è anche una trasformazione delle emozioni personali (in questo senso possiamo definirle come lavoro emotivo-affettivo) in valore attraverso una specifica infrastruttura digitale (Facebook Ads Manager).
- Il processo di trasformazione e le fonti di valorizzazione nell’economia della piattaforma
La creazione di valore riferito ai dati (o valore di rete) [6,39], attraverso l’elaborazione di dati digitali e linguaggi all’interno di un algoritmo, avviene principalmente in alcuni settori, con diversi tipi di piattaforme.
Secondo la letteratura [8,40,41,42], possiamo identificare sei tipi principali di piattaforme. L’elenco aumenterebbe probabilmente in funzione delle dinamiche del processo di accumulazione e valorizzazione attraverso l’economia digitale, in termini di produzione, vita sociale e politica:
- Piattaforme pubblicitarie (advertising platforms)come Google e Facebook, che estraggono informazioni dai propri utenti per rivendere i loro profili sotto forma di spazi pubblicitari.
- Piattaforme Cloudcome Amazon Web Services, che creano hardware e software per i mercati dipendenti dal digitale e li affittano ad aziende di ogni tipo, creando monopoli sulla conoscenza.
- Piattaforme industriali come General Electric o Siemens, che costruiscono hardware e software a costi di produzione inferiori, producendo e trasformando i beni in servizi (la così detta Industria 4.0).
- Piattaforme di prodotto come Spotify, che genera profitti affidandosi ad altre piattaforme che trasformano una merce come la musica in un servizio, e guadagnano attraverso la quota di abbonamento pagata agli abbonati al suddetto servizio.
- Work platform come Uber, Airbnb, Deliveroo o Foodora, che organizzano la forza lavoro attraverso un algoritmo e collegano clienti e imprese traendo profitto dalla riduzione del costo del lavoro.
- Piattaforme logistiche come Amazon, che regolano la logistica e il trasferimento delle merci.
Le piattaforme raccolgono i dati per poi elaborarli. Essi sono un input produttivo in un ciclo produttivo immateriale, i cui output (pubblicità, relazioni, induzione al consumo, etc.) producono un valore di scambio (“valore dei dati”), sulla base dell’appropriata tecnologia algoritmica (la stessa piattaforma).
Tuttavia, questo processo è ben lungi dall’essere omogeneo e preciso. Infatti, nella gestione dei cloud nella logistica [43] (cioè dei big data) c’è confusione, approssimazione ed eterogeneità, anche a causa dell’imperfezione delle tecnologie utilizzate, che vengono continuamente migliorate, anche grazie al coinvolgimento dei fornitori di dati e degli utenti.
Si pensi, ad esempio, al servizio di traduzione offerto da Google; la differenza rispetto ad altri sistemi di traduzione riguarda l’utilizzo di un dataset più ampio e molto caotico. Non si tratta di una traduzione parola per parola, ma di un’analisi di milioni di testi ufficiali che provengono da fonti come le Nazioni Unite e che forniscono grandi quantità di dati:
“Nonostante la confusione degli input, il sistema di Google funziona meglio. Le sue traduzioni sono più accurate di quelle offerte da altri sistemi. Ed è molto, molto più ricco. A metà del 2012, il suo set di dati copriva oltre 60 lingue. È stato persino in grado di accettare l’input vocale in 14 lingue per rendere le traduzioni più fluide. E poiché tratta la lingua semplicemente come una massa caotica di dati a cui applicare il calcolo delle probabilità, può anche tradurre tra due lingue come l’hindi e il catalano”.[44] (p. 132)
L’esempio del traduttore di Google è paradigmatico del processo di valorizzazione del capitalismo della piattaforma e della manipolazione dei big data. Da un lato, l’algoritmo è in grado di integrare attraverso una data procedura tutte le informazioni e i suggerimenti liberamente forniti dalla cooperazione sociale (general intellect) di cui il servizio di traduzione ha bisogno; dall’altro, la crescente accuratezza del servizio è una delle possibili ragioni della leadership di Google nello spazio Web [45].
Il meccanismo tradizionale viene poi sostituito da meccanismi più disordinati e flessibili, come il tagging, ampiamente utilizzato su Internet. Questo sistema permette di etichettare principalmente foto o video, al fine di rendere tracciabili i numerosi contenuti disponibili in rete, attraverso tags creati dagli utenti. La confusione in questo caso può essere dovuta all’errata scrittura dei tags e al modo in cui sono organizzati. Tutto questo, però, permette un accesso più ampio ai vari dati con un universo più ricco di etichette.
L’eterogeneità dei dati e le possibili varianti dei big data possono essere evidenziati nella seguente tabella 1.
Tabella 1. Possibili varianti dei big data: tassonomia di Davemport.
| Tipo di dati | Fonti dei dati | Settore | Funzione |
| Grandi volumi | Online | Servizi finanziari | Marketing |
| Non strutturati | Video | Salute | Logistica |
| Flussi continui | Sensori | Manifattura | Risorse Umane |
| Formati multipli | Genomics | Turismo/Trasporti | Finanza |
Fonte: Davemport, 2014 [46].
Questa classificazione, discutibile come qualsiasi tassonomia, evidenzia un settore trasversale che possiamo definire di business intelligence. Si tratta di una funzione aziendale che ha lo scopo di estrarre valore dai dati al fine di svolgere diverse finalità produttive. Si riferisce a:
“L’insieme dei processi aziendali per la raccolta dei dati e l’analisi delle informazioni strategiche, la tecnologia utilizzata per implementare tali processi e le informazioni ottenute come risultato di tali processi”.[46] (p. 54)
La business intelligence è quindi un sistema di modelli, metodi, processi, persone e strumenti che permettono di raccogliere e distribuire regolarmente i dati generati da un’azienda attraverso elaborazioni, analisi e aggregazioni. Il risultato è che la conoscenza viene trasformata in informazioni utilizzabili in modo semplice, flessibile ed efficace a supporto di decisioni strategiche, tattiche e operative.
Il sistema di business intelligence coinvolge:
– La raccolta dei dati aziendali;
– La loro pulizia, validazione e integrazione;
– La successiva elaborazione, aggregazione e analisi dei dati;
– L’uso fondamentale di questa quantità di informazioni nei processi strategici e di miglioramento.
In questo modo è possibile strutturare un vero e proprio ciclo di vita della valorizzazione del sistema dei big data, che può essere descritto sulla base di una successione di operazioni che iniziano con la “cattura/appropriazione dei dati”, la loro “organizzazione”, “integrazione”, “analisi” e “messa in azione”.
Nella stragrande maggioranza dei casi, soprattutto per quanto riguarda i dati non strutturati (circa l’80% del totale), questi dati vengono creati come valori d’uso, prodotti e socializzati dagli utenti/consumatori nello svolgimento delle attività quotidiane di cooperazione e relazione. Non a caso si parla di cattura o meglio di espropriazione più o meno forzata o volontaria.
Questo ciclo di vita descrive, in poche parole, il processo di valorizzazione dei big data. Vale la pena soffermarsi sulle due operazioni di “organizzazione” e di “integrazione”. Sono due operazioni che solo negli ultimi anni hanno raggiunto un certo grado di sofisticazione, grazie all’evoluzione tecnologica degli algoritmi di seconda generazione. L’organizzazione e l’integrazione dei dati è alla base della produzione di valore (ciò che è stato chiamato data value o network value). È l’aspetto produttivo del valore di scambio, mentre “l’analisi” e “la messa in azione” ne rappresentano la commercializzazione: cioè la realizzazione monetaria sui mercati finali.
Il “capitalismo delle piattaforme” comincia ad essere strutturato. Ci riferiamo alla capacità delle aziende di definire una nuova composizione del capitale in grado di gestire in modo sempre più automatizzato un processo di divisione dei dati in base all’uso commerciale che ne può derivare. Si basa sulla partecipazione, più o meno consapevole, di singoli utenti, ora trasformati in prosumer. Sono infatti gli utenti, interagendo con le piattaforme, attraverso le quali comunicano e si relazionano in varie forme, che forniscono la materia prima che viene poi inglobata nell’organizzazione capitalistica produttiva [47]. Il machine learning è diventato oggi lo strumento principale per la capacità del capitale di sussumere e catturare la cooperazione sociale, trasformando profondamente il tradizionale modo di produzione capitalista. Per questo motivo, alcuni studiosi hanno proposto di utilizzare l’espressione “comunismo del capitale” [48,49]. Il termine “comunismo del capitale” è stato originariamente proposto da Paolo Virno per caratterizzare il periodo post-fordista in cui il capitale si riorganizzava, mobilitando “a proprio beneficio precisamente quelle condizioni materiali e culturali che assicurerebbero un pacato realismo alla prospettiva comunista”[50] (p. 110).
Gli algoritmi sono alla base del machine learning. Per algoritmo si intende una procedura di calcolo, un metodo per risolvere un problema o una sequenza di istruzioni che dice al computer cosa fare.
Per comprendere la potenza del machine learning, possiamo ricorrere ad un’analogia riportata da Pedro Domingos, in cui questo tipo di tecnologia viene confrontato con l’agricoltura: gli algoritmi di apprendimento sono i semi, i dati sono il terreno e i programmi appresi sono le piante adulte [3]. L’esperto di machine learning è l’agricoltore che pianta i semi, irriga e fertilizza il terreno senza ulteriori interferenze. Grazie a questa metafora emergono due aspetti:
- Il primo è legato alla grande quantità di dati, perché più ne abbiamo, più possiamo imparare. La diffusione del machine learning è strettamente legata alla comparsa deibig data.
- Il secondo aspetto mostra invece come una montagna di dati disponibili possa ridurre la complessità che caratterizza questi processi. Con il machine learning, il processo subisce una forte accelerazione.
“La rivoluzione industriale ha automatizzato il lavoro manuale, e la rivoluzione dell’informazione ha fatto lo stesso con il lavoro intellettuale. Ilmachine learning, invece, automatizza l’automazione stessa: se non ci fosse, i programmatori diventerebbero dei colli di bottiglia che frenano il progresso” [3] (p. 14).
Gli algoritmi ci aiutano a navigare nella vastità dei dati sul Web, ma soprattutto sono in grado di influenzare le nostre decisioni e il nostro contesto culturale. Svolgono questa funzione proprio gli algoritmi delle piattaforme di social networking; ogni volta che li usiamo, lasciamo informazioni che vengono registrate, elaborate e utilizzate da altri utenti. Si tratta di una raccolta di informazioni individuali destinate successivamente alla comunità. Quando gli algoritmi suggeriscono ciò che ci piace e ci aiutano nelle nostre relazioni, cominciano a plasmare la nostra identità e a influenzare le nostre scelte. Nella società dell’informazione il problema principale sta nella quantità o, meglio, nella scelta illimitata che i big data creano: tra la molteplicità dei prodotti da scegliere o delle opportunità da cogliere, quale potrebbe essere il più adatto a noi? Algoritmi e machine learning offrono una soluzione. Nelle aziende, le operazioni da svolgere aumentano nel tempo, così come il numero di clienti può aumentare significativamente. Di conseguenza, il machine learning diventa fondamentale:
“Amazon non può codificare adeguatamente i gusti di tutti i suoi clienti in un programma, e Facebook non è in grado di scrivere un programma che sceglie gli aggiornamenti migliori da mostrare a ciascuno dei suoi utenti. Walmart, il gigante della distribuzione, vende milioni di prodotti e deve prendere miliardi di decisioni al giorno: se i suoi programmatori provassero a scrivere un programma dedicato, non finirebbero mai. La soluzione adottata da queste aziende, invece, è quella di scatenare gli algoritmi di apprendimento sulle montagne di dati che si sono accumulati e far loro indovinare cosa vogliono i clienti”.[3] (p. 17)
Gli algoritmi non sono perfetti ma, fornendo i loro risultati, influenzano gli utenti e le loro decisioni. Sono gli intermediari tra dati e consumatori e concentrano la potenza e il controllo come moderne catene di montaggio.
- Digital Labour o Digital Work?
Il caso Facebook che abbiamo presentato nella sezione precedente è un buon esempio di piattaforma pubblicitaria (advertising platform). Allo stesso tempo, il modello di creazione di valore di Facebook sembra trasformare la natura stessa del business. Inoltre, lo straordinario volume di big data rappresenta il risultato di un complesso processo di produzione che suggerisce di ripensare la distinzione cruciale tra labour e work. Nell’ultimo decennio, infatti, uomini d’affari, scienziati sociali e politici hanno introdotto la nozione di “digitallabour” per intendere due diverse situazioni innovative nel mercato del lavoro:
- Il digital labour è stato utilizzato per descrivere la forza lavoro di lavoratori indipendenti che lavorano per conto proprio e a proprio rischio e pericolo in cambio di bassi salari e senza sicurezza sociale, come nel caso di molti modelli di business basati su piattaforme come Uber, Foodora o altre work platforms e piattaforme logistiche.
- Per digital labour si intende anche l’attività umana utilizzata da altri modelli di business basati su piattaforme come Facebook o Google che si basano su una nuova composizione del capitale in grado di catturare le informazioni personali e trasformarle in big data.
Nel primo senso, i termini si riferiscono ad una forma classica di lavoro salariato caratterizzata da una profonda riduzione dei diritti dei lavoratori attraverso le tecnologie digitali. Di conseguenza, in questo caso, suggeriamo di abbandonare la nozione di digital labour e di utilizzare la nozione di digital work.
Nel secondo senso, i termini implicano fonti innovative di valorizzazione. Il digital labour,in senso proprio, introduce nuove forme di sfruttamento che vanno oltre il classico rapporto salariale.
La scomparsa di una chiara distinzione tra tempo di vita e tempo di lavoro è uno dei tratti distintivi del digitallabour e spiega perché questo concetto sia diventato cruciale nelle discussioni nell’ambito dell’economia politica di Internet [51,52], della sociologia del lavoro [53,54,55,56], degli studi Marxiani e soprattutto dell’ipotesi del capitalismo (bio)cognitivo [57,58,59,60,61].
Come scrivono Christian Fuchs e Sebastian Sevignani:
“L’argomento di base di questo dibattito è che il modello dominante di accumulazione di capitale delle piattaforme Internet aziendali contemporanee si basa sullo sfruttamento del lavoro non retribuito degli utenti, che si impegnano nella creazione di contenuti e nell’uso di blog, siti di social networking, wiki, micro blog, siti di condivisione di contenuti per divertimento e in queste attività creano valore che è al centro della generazione di profitto”.[9] (p. 237)
Per quanto riguarda il digital labour e il digital work, il nostro punto di vista si differenzia dall’analisi di Fuchs e Sevignani. Combinando il pensiero di Marx con la riflessione filosofica di Hegel riguardo la natura del lavoro, questi studiosi sostengono che la creatività, l’autoregolamentazione e la dimensione sociale del lavoro sono considerati e riconosciuti specialmente nella società digitale. Riconoscono che il digital labour viene sfruttato, anche se lo sfruttamento non viene percepito correttamente e consapevolmente perché il digital labour è concepito come lavoro ludico. Di conseguenza, nasconde la realtà dello sfruttamento dietro il divertimento di connettersi e incontrare altri utenti. Tuttavia, Fuchs e Sevignani tendono a prendere troppo alla leggera la rilevanza della nuova composizione del capitale in grado di catturare informazioni personali e trasformarle in big data. Affermano invece che Facebook è un regno di attività cognitive, comunicative e cooperative che sono lavoro nel senso di work. Per giustificare la loro tesi, Fuchs e Sevignani scrivono che:
“secondo Marx, per parlare di lavoro (work), deve esserci un’interazione della forza lavoro con oggetti e strumenti di lavoro, in modo che i valori d’uso siano creati come prodotti” (ivi, p. 255).
Tuttavia, è difficile considerare gli utenti di Facebook come lavoratori sfruttati. Facebook non organizza direttamente la cooperazione sociale degli utenti e non li concepisce come parte di una classe operaia, cioè di persone che devono lavorare per ottenere denaro. Come abbiamo sostenuto nei paragrafi precedenti, la cooperazione è organizzata al di là del luogo di lavoro ed è sempre più indipendente dal controllo diretto di Facebook. L’azienda lanciata da Mark Zuckerberg acquisisce informazioni personali. Come chiaramente dimostrato da Tiziana Terranova, Facebook può essere concepito come un prodotto del “lavoro gratuito” (free labour) [62] in cui i prosumers producono e utilizzano il sito di social networking per comunicare e sviluppare le proprie reti sociali, e allo stesso tempo contribuiscono alla creazione del prodotto principale di Facebook: i dati degli utenti e l’attenzione del pubblico.
La grande industria dei dati crea valore sulla base di un processo produttivo di cui la materia prima è la vita degli individui. Questa “materia prima” è in gran parte fornita gratuitamente.
Il “segreto” dell’accumulazione sta nella trasformazione delle informazioni personali in valore di scambio. In altre parole, sta nella trasformazione del lavoro concreto, che è alla base delle attività quotidiane degli utenti che generano dati attraverso relazioni sociali e bisogni di informazione, in lavoro astratto.
Secondo Marx [63] (Volume 1, Sezione 1.2), il lavoro concreto, qualitativamente definito, è finalizzato a produrre valore d’uso; il lavoro astratto, invece, è la pura manifestazione della forza lavoro umana (Arbeitsvermögen) [64] (pp. 81-125.), che è indipendente dagli aspetti qualitativi e dalle determinazioni specifiche riferite all’utilità delle singole opere e la cui quantità determina il valore creato. Nell’industria digitale, il lavoro astratto è l’organizzazione e l’integrazione dei dati.
In cosa consiste il processo di trasformazione delle informazioni personali in big data?
Nella prima fase si realizza un processo di accumulazione originaria come estensione della base produttiva per incorporare la vita, che però non è salariata o remunerata; nella maggior parte dei casi si tratta di una partecipazione passiva e non agita dal “soggetto”.
Nella seconda fase, subentra l’utilizzo di una forza lavoro organizzata (e retribuita), che procede all’attività di trasformazione. Qui diventa cruciale il modello di organizzazione del lavoro che viene implementato dall’algoritmo.
In altre parole, possiamo dire che la produzione digitale e il capitalismo delle piattaforme mostrano il “duplice carattere del capitalismo” [63] (Volume 1, Sezione 1.2).
Secondo Marx, quando il lavoro concreto è dominante, ci troviamo di fronte a un “processo lavorativo” in grado di soddisfare i bisogni e i sogni umani. Questo lavoro è definito da Marx come “necessario” ed è il naturale funzionamento intrinseco della vita umana.
Al contrario, quando il lavoro astratto è dominante, come avviene nel sistema capitalistico di produzione, il processo di lavoro dà origine ad un processo di valorizzazione e il lavoro necessario diventa lavoro in eccedenza.
L’attività digitale inizia normalmente come lavoro concreto e diventa lavoro astratto. Questo è il ruolo giocato dal capitalismo delle piattaforme.
Il sistema capitalistico di produzione è caratterizzato da una continua evoluzione dell’organizzazione del lavoro. Nel momento in cui il lavoro salariato si riduce, l’ozio e il tempo libero sono valorizzati. Tuttavia, lungi dal favorire la trasformazione del lavoro in opus e/o in otium, accade il contrario. Sono sempre più le capacità cognitive, artistiche e umane che sono mercificate, salariate e gerarchizzate. Lungi dall’entrare nell’era della “fine del lavoro”, siamo in presenza di un’era del “lavoro senza fine”.
Come si misura il tempo di vita quando diventa produttivo? Finché la prestazione di lavoro era direttamente correlata alla dimensione materiale, è stata misurata in termini di tasso di produttività, stimato sia in termini di unità di tempo (quante ore sono necessarie per produrre una certa quantità di output?) o in termini di quantità ottenute (quante unità di output sono prodotte in un dato intervallo di tempo?). Nel suo ultimo libro, Trebor Scholz affronta gli stessi problemi:
“La nostra identità online, così solertemente realizzata, ha un curioso aldilà in data centers lontani dove le soggettività e i dati sono trasformati in valore monetario. Senza essere riconosciuti come lavoro, la nostra posizione, le nostre espressioni e il tempo trascorso in rete possono essere trasformati in valore economico. Il monitoraggio e la monetizzazione degli utenti è spesso giustificato dai significativi costi operativi dei gestori delle piattaforme. Non è chiaro, tuttavia, cosa viene registrato esattamente, come viene misurato il suo valore, a chi viene venduto e per quale scopo”.[10] (p. 69)
Considerando il modello di creazione del valore di Facebook, possiamo proporre un esempio paradigmatico; il valore si basa essenzialmente su un processo di espropriazione delle capacità vitali (life skills) degli individui (o da ciò che possiamo definire, in senso lato, general intellect[65] e riproduzione sociale [35]) a fini di accumulazione privata. Il processo di creazione di valore non si limita più al singolo giorno lavorativo, ma si estende a tutta l’esistenza umana, cioè la vita che è necessaria per generare, ancora una volta, forza fisica, ma anche affetti, relazioni sociali e immaginari, e quindi sapere sociale. Il capitalismo delle piattaforme si propone di fornire una misura imponendo logiche di business su tutti gli aspetti della vita umana mediante l’utilizzo di diverse infrastrutture.
La nostra analisi sembra alloraconfermare alcune ipotesi avanzate dal cosiddetto approccio neo-operaista. Può essere riassunta nel modo seguente:
“Il processo, descritto come il ‘divenirerendita del profitto’ (Marazzi, 2010 [66]; Vercellone, 2010 [67]) diventa qui evidente: Facebook non raccoglie un profitto semplicemente organizzando il lavoro retribuito dei suoi relativamente pochi dipendenti (come suggerirebbe la teoria del processo lavorativo), ma estrae una rendita dai beni comuni prodotti dal lavoro gratuito dei suoi utenti”.[68] (p. 2).
- Conclusioni preliminari
Il modello di creazione di valore utilizzato da Facebook (Sezione 2.2.2) è un tipico esempio di capitalismo delle piattaforme che può essere visto come una forma specifica di capitalismo in cui la posta centrale dell’estrazione e dell’accumulazione di valore porta ad un controllo e ad una privatizzazione sempre maggiore della produzione collettiva di conoscenza [69]. La diffusione dei processi digitalizzati sta portando il capitalismo contemporaneo verso nuove frontiere. Come abbiamo sostenuto in precedenza (Sezione 4), le attività umane sulle piattaforme Internet sono sempre più integrate con gli elementi digitali della comunicazione e del linguaggio; il risultato porta ad una nuova forma di relazione tra lavoro concreto e lavoro astratto, utilizzando la terminologia marxiana (Sezione 3). Proponiamo quindi di definire il digitallabour come l’insieme delle attività umane realizzate al di fuori dell’orario di lavoro, catturate da modelli di business basati su piattaforme e trasformate in valore sotto forma di big data.
Le ricerche future dovrebbero approfondire l’evoluzione antropologica che sta influenzando sia le nozioni di lavoro che di svago; ad esempio, l’intera economia dei social media dei “Like”è progettata sulla base delle emozioni (l’esperimento di contagio emotivo condotto da Facebook è un esempio di quanto questi tentativi siano in grado di influenzare la nostra vita [70]).
Il capitalismo delle piattaforme (e in particolare il modello di Facebook) rappresenta la frontiera del domani. Il nuovo paradigma tecnologico basato sul lavoro digitale può cambiare profondamente il nostro modo di intendere le relazioni sociali, economiche e politiche. Qui si pone il problema della sostenibilità antropologica.
Contributi degli autori
Tutti gli autori hanno contribuito in modo sostanziale all’intero lavoro riportato. Hanno letto e approvato il manoscritto finale. Andrea Fumagalli ha concepito il quadro teorico e ha contribuito la stesura delle Sezioni 1, 3 e 4. Stefano Lucarelli ha sviluppato in particolare la critica della tesi di Fuchs e Sevignani e ha scritto le Sezioni 1, 4 e 5. Giulia Rocchi ha effettuato l’analisi del modello di business di Facebook e ha scritto la Sezione 2. Elena Musolino ha contribuito alla rassegna della letteratura, alla redazione del testo e alla focalizzazione della differenza tra digital labour e digital work presentata nella Sezione 4.
Ringraziamenti
Gli autori desiderano ringraziare i tre referee anonimi della rivista Sustainability per i loro utili suggerimenti. Grazie anche a Effimera.org che rappresenta una preziosa esperienza collettiva di pensiero critico per discutere delle nuove tendenze del capitalismo contemporaneo, in particolare a Cristina Morini. Parte dell’analisi è stata discussa con i membri del Laboratorio CES-CNRS UMR-8174 e con i membri del NEXA-Politecnico di Torino nell’ambito del progetto DECODE (finanziato dal Programma Horizon 2020 dell’Unione Europea – sovvenzione numero 732546). Per questo motivo, gli autori ringraziano in particolare Carlo Vercellone, Jean-Marie Monnier e Marco Ciurcina.
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
BIBLIOGRAFIA
-
All about the Human Genome Project (HGP). Available online:https://www.genome.gov/10001772/all-about-the–human-genome-project-hgp/ (accessed on 1 March 2018).
-
Boyer, R.The Future of Economic Growth; Eward Elgar: Cheltenham, UK, 2004; p. 136. [Google Scholar]
-
Domingos, P.The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World; Basic Books: New York, NY, USA, 2015. [Google Scholar]
-
McKynsey Global Institute, Big Data: The Next Frontier for Innovation, Competition and Productivity. May 2011. Available online:https://www.mckinsey.com/business-functions/digital-mckinsey/our-insights/big-data-the-next-frontier-for-innovation (accessed on 16 May 2018).
-
Kenney, M.; Zysman, J. The Rise of the Platform Economy.Issues Sci. Technol. 2016, 32, 61. Available online: http://issues.org/32-3/the-rise-of-the-platform-economy/ (accessed on 16 May 2018). [Google Scholar]
-
Fumagalli, A. Per una teoria del valore-rete: Big data e processi di sussunzione. InSocietà, Cultura e Conflitti al Tempo dei Big Data; Gambetta, D., Ed.; D Editore: Roma, Italy, 2018. [Google Scholar]
-
Gandomi, A.; Haider, M. Beyond the hype: Big data concepts, methods, and analytics. J. Inf. Manag.2015, 35, 137–144. [Google Scholar] [CrossRef]
-
Srnicek, N.Platform Capitalism; Polity Press: Cambridge, UK, 2017. [Google Scholar]
-
Fuchs, C.; Sevignani, S. What is Digital Labour? What is Digital Work? What’s their Difference? And why do these Questions Matter for Understanding Social Media?tripleC 2013, 11, 237–293. [Google Scholar] [CrossRef]
-
Scholz, T.Uberworked and Underpaid. How Workers are Disrupting the Digital Economy; Polity Press: Cambridge, UK, 2017. [Google Scholar]
-
Available online:https://www.statista.com/statistics/264810/number-of-monthly-active-facebook-users-worldwide/ (accessed on 1 March 2018).
-
Facebook Annual Report (2016). Available online:http://www.annualreports.com/Company/facebook(accessed on 1 March 2018).
-
Statcounter, GlobalStats. Available online:http://gs.statcounter.com/platform-market-share/desktop-mobile-tablet/worldwide (accessed on 1 March 2018).
-
Boyd, D.; Ellison, N.B. Social network sites: Definition, history, and scholarship.Comput. Med. Commun. 2008, 13, 210–230. [Google Scholar] [CrossRef]
-
Gebika, A.; Heinemann, A. Social Media & Competition Law.World Compet. 2014, 37, 149–172. [Google Scholar]
-
Phillips, S. A Brief History of Facebook.The Guardian, 25 July 2017. Available online: https://www.theguardian.com/technology/2007/jul/25/media.newmedia(accessed on 1 March 2018). [Google Scholar]
-
Available online:https://www.techwyse.com/blog/infographics/65-facebook-acquisitions-the-complete-list-infographic/ (accessed on 1 March 2018).
-
Facebook Partner Categories. Available online:https://www.facebook.com/business/a/facebook-partner-categories (accessed on 1 March 2018).
-
Marshall, J. Facebook Extends Reach with New Advertising Platform.The Wall Street Journal, 22 September 2014. Available online: https://www.wsj.com/articles/facebook-extends-reach-withad-platform-1411428726/(accessed on 1 March 2018). [Google Scholar]
-
Available online:https://atlassolutions.com/2016/03/07/value-with-atlas/ (accessed on 1 March 2018).
-
Meola, A. Facebook Is Shutting down Facebook Exchange.Business Insider, 26 May 2016. Available online: http://www.businessinsider.com/facebook-is-shutting-down-acebookexchange-2016-5?IR=T(accessed on 1 March 2018). [Google Scholar]
-
Shields, M. Facebook Plans to Shut Down Video Ad Exchange Product LiveRail.The Wall Street Journal, 26 May 2016. Available online: https://www.wsj.com/articles/facebook-plans-to-shut-downvideo-ad-exchange-product-liverail-1464303877(accessed on 1 March 2018). [Google Scholar]
-
Peterson, T. How Facebook Turned an End-to-End Ad Tech Strategy on Its Head.Marketing Land, 17 June 2016. Available online: https://marketingland.com/facebook-turned-end-end-ad-tech-strategy-head-181395(accessed on 1 March 2018). [Google Scholar]
-
Available online:https://info.internet.org/en/ (accessed on 1 March 2018).
-
Open Letter to Mark Zuckerberg Regarding Internet.org, Net Neutrality, Privacy, and Security. 2015. Available online:https://www.facebook.com/notes/access-now/open-letter-to-mark-zuckerberg-regarding-internetorg-net-neutrality-privacy-and-/935857379791271/ (accessed on 1 March 2018).
-
Available online:https://www.emarketer.com/Article/Social-Media-Marketers-Facebook-Produces-Best-ROI/1013918 (accessed on 1 March 2018).
-
Available online:http://fortune.com/company/pgpef/ (accessed on 1 March 2018).
-
Available online:https://www.zenithmedia.com/google-facebook-now-control-20-global-adspend/(accessed on 1 March 2018).
-
Business Facebook. Available online:https://business.facebook.com/ (accessed on 1 March 2018).
-
Facebook for Developers. Available online:https://developers.facebook.com/?locale=en_UK (accessed on 1 March 2018).
-
Chaykowski, K. Facebook Extends Its Ad Network To Mobile Websites.Forbes, 20 January 2016. Available online: https://www.forbes.com/sites/kathleenchaykowski/2016/01/26/facebook-extends-its-ad-network-to-the-mobile-web/#1fe829b7132e(accessed on 1 March 2018). [Google Scholar]
-
Slefo, G. Facebook to Serve Ads to Non-Users through Its Audience Network.Advertising Age, 27 May 2016. Available online: http://adage.com/article/digital/facebook-serve-ads-users-audience-network/304195/(accessed on 1 March 2018). [Google Scholar]
-
Facebook Business. Available online:https://en-gb.facebook.com/business (accessed on 1 March 2018).
-
Audience Network by Facebook. Available online:https://www.facebook.com/audiencenetwork (accessed on 1 March 2018).
-
Dewey, C. 98 Personal Data Points that Facebook Uses to Target Ads to You.The Washington Post, 19 August 2016. Available online: https://www.washingtonpost.com/news/theintersect/wp/2016/08/19/98-personal-data-points-that-facebook-uses-to-target-ads-toyou/?utm_term=.038a29370111(accessed on 1 March 2018). [Google Scholar]
-
Morini, C. Social Reproduction as a Paradigm of the Common. Reproduction Antagonism, Production Crisis. InPost-Crisis Perspectives; Augustin, O., Ydesen, C., Eds.; Peter Lang: Frankfurt, Germany; New York, NY, USA, 2013; pp. 83–98. [Google Scholar]
-
Fumagalli, A.;Morini, C. Life put to work: Towards a life theory of value. TheoryPolit. Organ. 2010, 10, 234–252. [Google Scholar]
-
Codeluppi, V.Il Biocapitalismo. Verso lo Sfruttamento Integrale di Corpi, Cervelli ed Emozioni; Bollati Boringhieri: Torino, Italy, 2008. [Google Scholar]
-
Pasquinelli, M. Italian Operaismo and the Information Machine.Theory Cult. Soc. 2015, 32, 49–68. [Google Scholar] [CrossRef]
-
Smith, A. Gig Work, Online Selling and Home Sharing. Pew Research Center, 17 November 2016. Available online:http://www.pewinternet.org/2016/11/17/gig-work-online-selling-and-home-sharing/ (accessed on 1 March 2018).
-
Vecchi, B.Il Capitalismo delle Piattaforme; Manifestolibri: Roma, Italy, 2017. [Google Scholar]
-
Tarleton, G. The Platform Metaphor, Revisited. Alexander Von Humboldt Institutfür Internet und Gesellschaft, 24 August 2017. Available online:http://culturedigitally.org/2017/08/platform-metaphor/ (accessed on 1 March 2018).
-
Mosco, V.To the Cloud: Big Data in a Turbulent World; Paradigm Publishers: Boulder, CO, USA, 2014. [Google Scholar]
-
Mayer Schoenberger, V.; Cukier, K.Big Data: A Revolution that Will Transform How We Live, Work, and Think; Eamon Dolan Book: Boston, NY, USA, 2013. [Google Scholar]
-
Carr, N.The Big Switch: Rewiring the World, from Edison to Google; W.W. Norton & Company: New York, NY, USA, 2008. [Google Scholar]
-
Davemport, T.H.Big Data at Work: Dispelling the Myths, Uncovering the Opportunities; Harward Business Review Press: Boston, NY, USA, 2014. [Google Scholar]
-
Booth, A. Marx’s Capital: Chapter 15—The Machine. Available online:https://www.socialist.net/marx-s-capital-chapters-15-the-machine.htm (accessed on 20 April 2018).
-
Beyerungen, A.; Murtola, A.M.; Schwartz, G. The communism of capital. TheoryPolit. Organ. 2013, 13, 483–495. [Google Scholar]
-
Marazzi, C.Il Comunismo del Capitale. Biocapitalismo, Finanziarizzazione Dell’Economia e Appropriazioni del Comune; Ombre Corte: Verona, Italy, 2010. [Google Scholar]
-
Virno, P.A Grammar of the Multitude: For an Analysis of Contemporary Forms of Life; Semiotext(e): New York, NY, USA, 2004. [Google Scholar]
-
Burston, J.; Dyer-Witheford, N.; Hearn, A. Digital Labour: Workers, Authors, Citizens.TheoryPolit. Organ. 2010, 10, 214–221. [Google Scholar]
-
Scholz, T. (Ed.)Digital Labour. The Internet as Playground and Factory; Routledge: New York, NY, USA, 2012. [Google Scholar]
-
Huws, U.Labor in the Global Digital Economy: The Cybertariat Comes of Age; Monthly Review Press: New York, NY, USA, 2104. [Google Scholar]
-
Huws, U. New forms of platform employment. InThe Digital Economy and the Single Market; Wobbe, W., Bova, E., Dragomirescu-Gaina, C., Eds.; Foundation for European Progressive Studies: Brussels, Belgium, 2014; pp. 65–82. [Google Scholar]
-
Cardon, D.; Casilli, A. Qu’est-ce que le Digital Labor?INAGLOBAL, 7 September 2015. Available online: https://www.inaglobal.fr/numerique/article/quest-ce-que-le-digital-labor-8475#sommaire(accessed on 1 March 2018). [Google Scholar]
-
Arvidsson, A.; Colleoni, E. Value in Informational Capitalism on the Internet.Soc. 2012, 28, 135–150. [Google Scholar] [CrossRef]
-
Fumagalli, A.Bioeconomia e Capitalismo Cognitivo. Verso un Nuovo Paradigma di Accumulazione; Carocci: Roma, Italy, 2007. [Google Scholar]
-
Fumagalli, A. Twenty Theses on Contemporary Capitalism (Cognitive Biocapitalism).Angelaki 2011, 6, 7–17. [Google Scholar] [CrossRef]
-
Fumagalli, A.; Lucarelli, S. Valorization and financialization in cognitive biocapitalism. Manag. Financ. Innov. 2011, 8, 88–103. [Google Scholar]
-
Moulier-Boutang, Y.Le Capitalisme Cognitif: La Nouvelle Grande Transformation; Editions Amsterdam: Paris, France, 2008; (English Translation. Cognitive Capitalism; Translated by Emery, E.; Polity Press: New York, NY, USA, 2011). [Google Scholar]
-
Vercellone, C. (Ed.)Capitalismo cognitivo. Conoscenza e finanza nell’epoca postfordista; Manifestolibri: Roma, Italia, 2006. [Google Scholar]
-
Terranova, T.Network Culture: Politics for the Information Age; Pluto Press: London, UK, 2004. [Google Scholar]
-
Marx, K.Capital; Penguin Book: London, UK, 2004; Volume 1. [Google Scholar]
-
Ciccarelli, R.Forza Lavoro; DeriveApprodi: Roma, Italy, 2018. [Google Scholar]
-
Vercellone, C. From Formal Subsumption to General Intellect: Elements for a Marxist Reading of the Thesis of Cognitive Capitalism. Mater. 2007, 15, 13–36. [Google Scholar] [CrossRef][Green Version]
-
Marazzi, C.The Violence of Capital; Semiotext(e): New York, NY, USA, 2010. [Google Scholar]
-
Vercellone, C. The Crisis of the Law of Value and the Becoming-Rent of Profit. InCrisis in the Global Economy: Financial Markets, Social Struggles and New Political Scenarios; Fumagalli, A., Mezzadra, S., Eds.;Semiotext(e): New York, NY, USA, 2010; pp. 85–118. [Google Scholar]
-
Böhm, S.; Land, C.; Beverungen, A. The Value of Marx: Free Labour, Rent and ‘Primitive’ Accumulation in Facebook. Working Paper Series; University of Essex, May 2012. Available online:https://www.researchgate.net/publication/239735772 (accessed on 17 May 2018).
-
Vercellone, C.; Monnier, J.-M.; Lucarelli, S.; Griziotti, G. Theoretical Framework on Future Knwoledge-Based Economy. D3.1 of D-Cent European Project. 2014. Available online:https://dcentproject.eu/wp-content/uploads/2014/04/D3.1-final_new.pdf (accessed on 1 March 2018).
-
Sampson, T. Various joyful encounters with the dystopias of affective capitalism.TheoryPolit. Organ. 2016, 16, 51–74. [Google Scholar]








































Add comment